Como executar o Apache Spark no Kubernetes em menos de 5min

Ferramentas como o Ilum ajudarão muito a simplificar o processo de instalação do Apache Spark no Kubernetes. Este guia o guiará, passo a passo, por como executar bem o Spark em seu cluster Kubernetes. Com o Ilum, a implantação, o gerenciamento e o dimensionamento de clusters do Apache Spark são feitos de maneira fácil e natural.
Introdução
Hoje, mostraremos como começar a usar o Apache Spark no K8s. Há muitas maneiras de fazer isso, mas a maioria é complexa e requer várias configurações. Usaremos Ilum já que isso fará toda a configuração do cluster para nós. Na próxima postagem do blog, compararemos o uso com o operador Spark.
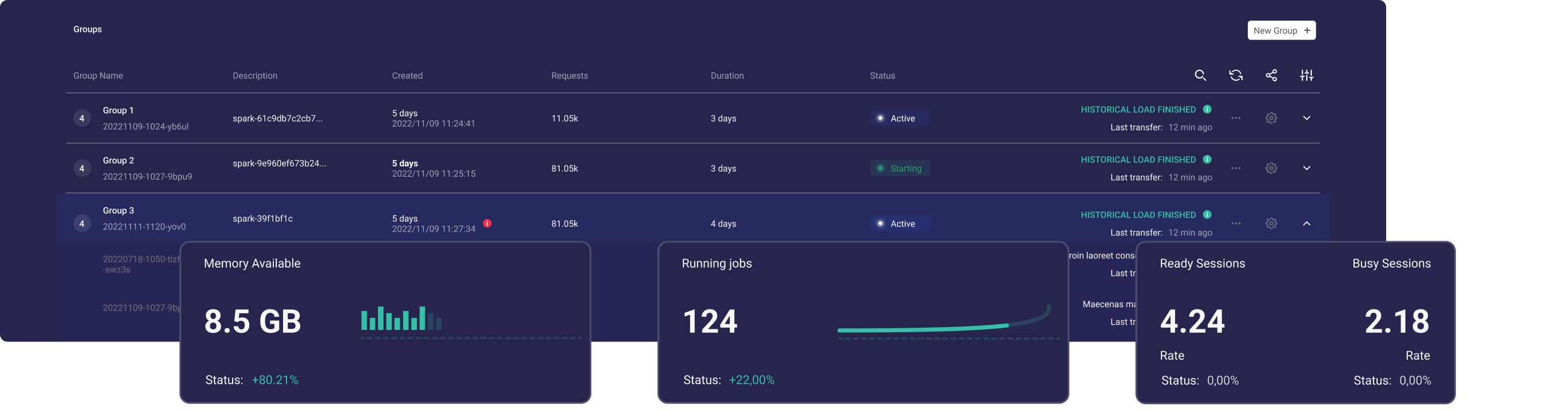
O Ilum é um data lakehouse modular gratuito para implantar e gerenciar facilmente clusters do Apache Spark. Possui uma API simples para definir e gerenciar o Spark, ele lidará com todas as dependências. Ele ajuda na criação de sua própria faísca gerenciada.
Com o Ilum, você pode implantar clusters do Spark em minutos e começar a executar aplicativos do Spark imediatamente. O Ilum permite que você escale horizontalmente e dimensione facilmente seus clusters do Spark, gerenciando vários clusters do Spark a partir de uma única interface do usuário.
Com o Ilum, começar é fácil se você for relativamente novo no Apache Spark no Kubernetes.
Guia passo a passo para instalar o Apache Spark no Kubernetes
Início rápido
Presumimos que você tenha um cluster do Kubernetes em execução, caso não tenha, confira estas instruções para configurar um cluster do Kubernetes no minikube. Confira como instalar o minikube .
Configurar um cluster do Kubernetes local
- Instale o Minikube: Execute o comando a seguir para instalar o Minikube junto com os recursos recomendados. Isso instalará o Minikube com 6 vCPUs e 12288 MB de memória, incluindo o complemento do servidor de métricas necessário para o monitoramento.
minikube start --cpus 6 --memory 12288 --addons metrics-server Depois de ter um cluster Kubernetes em execução, estão a apenas alguns comandos de instalar o Ilum:
Instale o Spark no Kubernetes com o Ilum
- Adicionar Repositório Ilum Helm
helm repo add ilum https://charts.ilum.cloud - Instalar o ilum em seu cluster
Here we have a few options.
a) The recommended one is to start with a few additional modules turned on (Data Lineage, SQL, Data Catalog).
helm install ilum ilum/ilum \
--set ilum-hive-metastore.enabled=true \
--set ilum-core.metastore.enabled=true \
--set ilum-sql.enabled=true \
--set ilum-core.sql.enabled=true \
--set global.lineage.enabled=trueb) you can also start with the most basic option which has only Spark and Jupyter notebooks.
Helm instalar e ile/el c) there is also an option to use ilum's module selection tool aqui .
minikube ssh docker pull ilum/core:6.6.0
Essa configuração deve levar cerca de dois minutos. O Ilum será implantado em seu cluster Kubernetes, preparando-o para lidar com trabalhos do Spark.
Depois que o Ilum estiver instalado, você poderá acessar a interface do usuário com port-forward e localhost:9777.
- Encaminhamento de porta para acessar a interface do usuário: Use o encaminhamento de porta do Kubernetes para acessar a interface do usuário do Ilum.
SVC/ILUM-UI de encaminhamento de porta kubectl 9777:9777 Usar admin/admin como credenciais padrão. Você pode alterá-los durante o Processo de implantação .
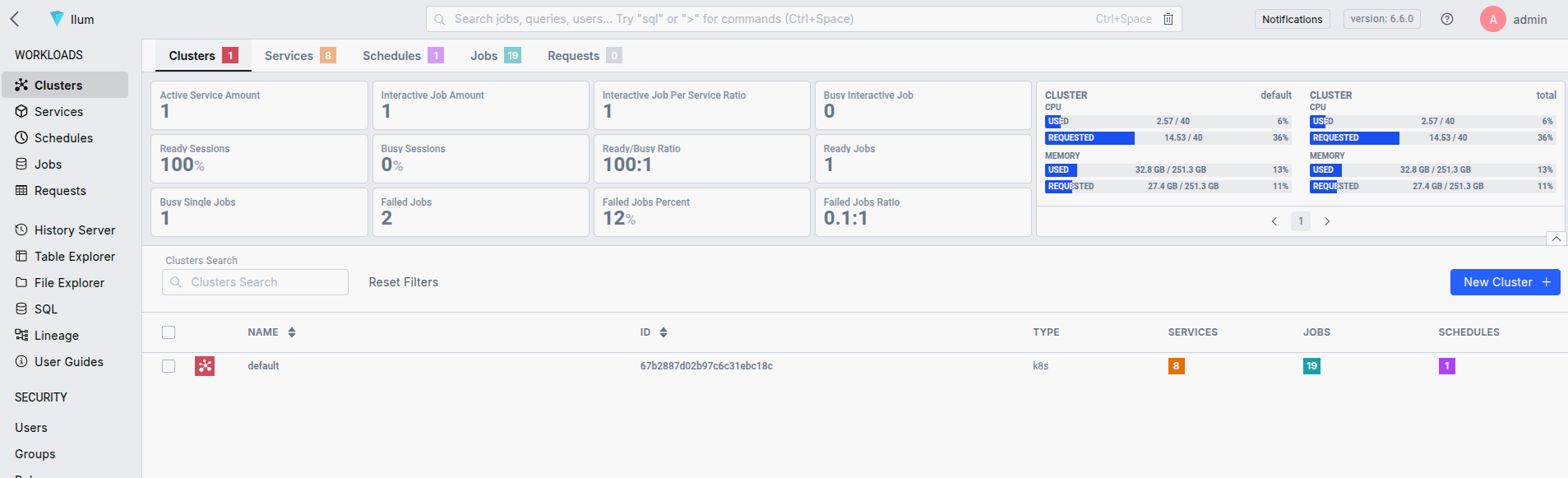
Isso é tudo, seu cluster kubernetes agora está configurado para lidar com trabalhos do Spark. O Ilum fornece uma API e interface do usuário simples que facilitam o envio de aplicativos Spark. Você também pode usar o bom e velho envio de faísca .
Implantar o aplicativo Spark no Kubernetes
Vamos agora começar um trabalho simples de faísca. Usaremos o exemplo "SparkPi" do Spark documentação . Você pode usar o arquivo jar deste link .
ilum adicionar trabalho de faísca
O Ilum criará um pod do kubernetes do driver Spark, ele usa a imagem docker do Spark versão 3.x. Você pode controlar o número de pods do executor do Spark dimensionando-os para vários nós. Essa é a maneira mais simples de enviar aplicativos de faísca para K8s.

Executar o Spark no Kubernetes é muito fácil e sem atrito com o Ilum. Ele configurará todo o cluster e apresentará uma interface na qual você pode gerenciar e monitorar o cluster do Spark. Acreditamos que os aplicativos Spark no Kubernetes são o futuro do big data. Com o Kubernetes, os aplicativos Spark poderão lidar com grandes volumes de dados de forma muito mais confiável, fornecendo insights exatos e podendo orientar decisões com big data.
Enviando um aplicativo Spark para o Kubernetes (estilo antigo)
O envio de um trabalho do Spark para um cluster do Kubernetes envolve o uso do envio de faísca script com configurações específicas do Kubernetes. Aqui está um guia passo a passo:
Passos :
-
Preparar o aplicativo Spark : Empacote seu aplicativo Spark em um arquivo JAR (para Scala/Java) ou um script Python.
-
Usar
envio de faíscapara implantar : Execute oenvio de faíscacom opções específicas do Kubernetes:./bin/spark-submit \ --master k8s://https://<k8s-apiserver-host>:<k8s-apiserver-port> \ --cluster do modo de implantação \ --nome spark-app \ --class org.apache.spark.examples.SparkPi \ --conf spark.executor.instances=3 \ --conf spark.kubernetes.container.image=<your-spark-image> \ local:///path/to/your-app.jarSubstituir:
<k8s-apiserver-host>: Seu host do servidor de API do Kubernetes.<k8s-apiserver-port>: Sua porta do servidor de API do Kubernetes.<your-spark-image>: a imagem do Docker que contém o Spark.local:///path/to/your-app.jar: Caminho para o JAR do aplicativo na imagem do Docker.
Configurações principais :
--senhor: Especifica a URL da API do Kubernetes.--modo de implantação: Defina comoclusterpara executar o driver dentro do cluster do Kubernetes.--nome: nomeia seu aplicativo Spark.--classe: Classe principal do seu aplicativo.--conf spark.executor.instances: Número de pods de executor.--conf spark.kubernetes.container.image: imagem do Docker para pods do Spark.
Para obter mais detalhes, consulte o Documentação do Apache Spark em execução no Kubernetes .
2. Criando uma imagem personalizada do Docker para o Spark
A criação de uma imagem personalizada do Docker permite empacotar seu aplicativo Spark e suas dependências, garantindo a consistência entre os ambientes.
Passos :
-
Criar um Dockerfile : Defina o ambiente e as dependências.
# Use a imagem base oficial do Spark DA faísca: 3.5.3 # Definir variáveis de ambiente ENV SPARK_HOME=/opt/spark ENV PATH=$PATH:$SPARK_HOME/bin # Copie o JAR do seu aplicativo para a imagem COPIAR your-app.jar $SPARK_HOME/exemplos/frascos/ # Defina o ponto de entrada para executar seu aplicativo ENTRYPOINT ["spark-submit", "--class", "org.apache.spark.examples.SparkPi", "--master", "local[4]", "/opt/spark/examples/jars/your-app.jar"]Neste Dockerfile:
DA faísca: 3.5.3: Usa a imagem oficial do Spark como base.ENV: Define variáveis de ambiente para o Spark.COPIAR: Adiciona o JAR do aplicativo à imagem.PONTO DE ENTRADA: Define o comando padrão para executar o aplicativo Spark.
-
Criar a imagem do Docker : Use o Docker para criar sua imagem.
docker build -t seu-repositório / seu-aplicativo-faísca: mais recente .Substituir
seu-repo/seu-aplicativo-spark-com o repositório do Docker e o nome da imagem. -
Enviar a imagem para um registro : carregue sua imagem em um registro do Docker acessível pelo cluster do Kubernetes.
docker push seu-repositório / seu-spark-app: mais recente
Ao usar envio de faísca é um método comum para implantar aplicativos Spark, pode não ser a abordagem mais eficiente para ambientes de produção. Os envios manuais podem levar a inconsistências e são difíceis de integrar em fluxos de trabalho automatizados. Para aumentar a eficiência e a capacidade de manutenção, é recomendável aproveitar a API REST do Ilum.
Automatizando implantações do Spark com a API REST do Ilum
A Ilum oferece uma API RESTful robusta que permite uma interação perfeita com clusters do Spark. Essa API facilita a automação de envios, monitoramento e gerenciamento de trabalhos, tornando-a a escolha ideal para pipelines de CI/CD (Integração Contínua/Implantação Contínua).
Benefícios de usar a API REST do Ilum:
- Automação : Integre envios de trabalho do Spark em pipelines de CI/CD, reduzindo a intervenção manual e possíveis erros.
- Consistência : Garanta processos de implantação uniformes em diferentes ambientes.
- Escalabilidade : gerencie facilmente vários clusters e trabalhos do Spark programaticamente.
Exemplo: Enviar um trabalho do Spark por meio da API REST do Ilum
Para enviar um trabalho do Spark usando a API REST do Ilum, você pode fazer uma solicitação HTTP POST com os parâmetros necessários. Aqui está um exemplo simplificado usando cacho :
curl -X POST https://<ilum-server>/api/v1/job/submit \
-H "Tipo de conteúdo: multipart/form-data" \
-F "nome=trabalho de exemplo" \
-F "nome_do_cluster = padrão" \
-F "jobClass=org.apache.spark.examples.SparkPi" \
-F "jars=@/caminho/para/your-app.jar" \
-F "jobConfig=spark.executor.instances=3; spark.executor.memory=4g" Neste comando:
nome: Especifica o nome do trabalho.nome_do_cluster: Indica o cluster de destino.classe de trabalho: Define a classe principal do aplicativo Spark.Frascos: Carrega o arquivo JAR do aplicativo.jobConfig: define as configurações do Spark, como o número de executores e a alocação de memória.
Para obter informações detalhadas sobre os endpoints e parâmetros da API, consulte o Documentação da API do Ilum .
Aumentando a eficiência com trabalhos interativos do Spark
Além de automatizar os envios de trabalhos, transformar os trabalhos do Spark em microsserviços interativos pode otimizar significativamente a utilização de recursos e os tempos de resposta. O Ilum suporta a criação de sessões interativas do Spark de longa duração que podem processar dados em tempo real sem a sobrecarga de inicializar um novo contexto do Spark para cada solicitação.
Vantagens do Interactive Spark Jobs:
- Latência reduzida : elimina a necessidade de iniciar um novo contexto do Spark para cada trabalho, levando a uma execução mais rápida.
- Otimização de recursos : Mantém um contexto persistente do Spark, permitindo o gerenciamento eficiente de recursos.
- Escalabilidade : lida com várias solicitações simultaneamente na mesma sessão do Spark.
Para implementar um trabalho interativo do Spark com o Ilum, você pode definir um aplicativo Spark que escuta os dados de entrada e os processa em tempo real. Essa abordagem é particularmente benéfica para aplicativos que exigem processamento e resposta de dados imediatos.
Para obter um guia abrangente sobre como configurar trabalhos interativos do Spark e otimizar seu cluster do Spark, consulte a postagem no blog do Ilum: Como otimizar seu cluster do Spark com trabalhos interativos do Spark .
Ao integrar a API REST do Ilum e adotar trabalhos interativos do Spark, você pode simplificar seus fluxos de trabalho do Spark, aprimorar a automação e obter um ambiente de processamento de dados mais eficiente e escalável.
Vantagens de usar o Ilum para executar o Spark no Kubernetes
O Ilum está equipado com uma interface de usuário intuitiva e uma API resiliente para dimensionar e lidar com clusters Spark, configurando alguns aplicativos Spark a partir de uma interface. Aqui estão alguns ótimos recursos a esse respeito:
- Facilidade de uso : O Ilum simplifica a configuração e o gerenciamento do Spark no Kubernetes com uma interface de usuário intuitiva do Spark, eliminando processos de configuração complexos.
- Implantação rápida: Configure, implante e dimensione clusters do Spark em minutos para acelerar o tempo de execução e teste de aplicativos imediatamente.
- Escalabilidade: Usando a API do Kubernetes, aumente ou diminua facilmente a escala dos clusters do Spark para atender às suas necessidades de processamento de dados, garantindo a utilização ideal dos recursos.
- Modularidade : O Ilum vem com uma estrutura modular que permite aos usuários escolher e combinar diferentes componentes, como Spark History Server, Apache Jupyter, Minio e muito mais.
Migrando do Apache Hadoop Yarn
Agora que o Apache Hadoop Yarn está em profunda estagnação, mais e mais organizações estão procurando migrar do Yarn para o Kubernetes. Isso é atribuído a vários motivos, mas o mais comum é que o Kubernetes fornece uma plataforma mais resiliente e flexível em questões de gerenciamento de cargas de trabalho de Big Data.
Geralmente, é difícil realizar uma migração de plataforma da plataforma de processamento de dados do Apache Hadoop Yarn para qualquer outra. Há muitos fatores a serem considerados quando essa mudança é feita - compatibilidade de dados, velocidade e custo de processamento. No entanto, seria tranquilo e bem-sucedido se o procedimento fosse bem planejado e executado.
O Kubernetes é praticamente um ajuste natural quando se trata de cargas de trabalho de Big Data devido à sua capacidade inerente de escalar horizontalmente. Mas, com o Hadoop Yarn, você está limitado ao número de nós em seu cluster. Você pode aumentar e reduzir o número de nós dentro de um cluster do Kubernetes sob demanda.
Ele também permite recursos que não estão disponíveis no Yarn, por exemplo: autocorreção e dimensionamento horizontal.
Hora de mudar para o Kubernetes?
À medida que o mundo do big data continua a evoluir, o mesmo acontece com as ferramentas e tecnologias usadas para gerenciá-lo. Durante anos, o Apache Hadoop YARN tem sido o padrão de fato para gerenciamento de recursos em ambientes de big data. Mas com o surgimento de tecnologias de conteinerização e orquestração como o Kubernetes, é hora de fazer a mudança?
O Kubernetes vem ganhando popularidade como plataforma de orquestração de contêineres, e por boas razões. É flexível, escalável e relativamente fácil de usar. Se você ainda estiver usando a infraestrutura tradicional baseada em VM, talvez seja a hora de mudar para o Kubernetes.
Se você estiver trabalhando com contêineres, definitivamente deve se preocupar com o Kubernetes. Ele pode ajudá-lo a gerenciar e implantar seus contêineres com mais eficiência e é especialmente útil se você estiver trabalhando com muitos contêineres ou se estiver implantando seus contêineres em uma plataforma de nuvem.
O Kubernetes também é uma ótima opção se você estiver procurando por uma ferramenta de orquestração apoiada por uma grande empresa de tecnologia. O Google usa o Kubernetes há anos para gerenciar seus próprios aplicativos em contêineres e investiu muito tempo e recursos para torná-lo uma ótima ferramenta.
Não há um vencedor claro no debate YARN vs. Kubernetes. A melhor solução para sua organização dependerá de suas necessidades específicas e casos de uso. Se você está procurando uma solução de gerenciamento de recursos mais flexível e escalável, vale a pena considerar o Kubernetes. Se você precisar de melhor suporte para aplicativos legados, o YARN pode ser uma opção melhor.
Seja qual for a plataforma que você escolher, a Ilum pode ajudá-lo a tirar o máximo proveito dela. Nossa plataforma foi projetada para funcionar com YARN e Kubernetes, e nossa equipe de especialistas pode ajudá-lo a escolher e implementar a solução certa para sua organização.
Cluster do Spark gerenciado
Um cluster gerenciado do Spark é uma solução baseada em nuvem que facilita o provisionamento e o gerenciamento de clusters do Spark. Ele fornece uma interface baseada na Web para criar e gerenciar clusters do Spark, bem como um conjunto de APIs para automatizar tarefas de gerenciamento de cluster. Os clusters gerenciados do Spark geralmente são usados por cientistas de dados e desenvolvedores que desejam provisionar e gerenciar rapidamente clusters do Spark sem precisar se preocupar com a infraestrutura subjacente.
O Ilum fornece a capacidade de criar e gerenciar seu próprio cluster do Spark, que pode ser executado em qualquer ambiente, incluindo nuvem, local ou uma mistura de ambos.

Os prós do Apache Spark no Kubernetes
Tem havido algum debate sobre se o Apache Spark deve ser executado no Kubernetes.
Algumas pessoas argumentam que o Kubernetes é muito complexo e que o Spark deve continuar a ser executado em seu próprio gerenciador de cluster dedicado ou permanecer na nuvem. Outros argumentam que o Kubernetes é o futuro do processamento de big data e que o Spark deve adotá-lo.
Estamos no último campo. Acreditamos que o Kubernetes é o futuro do processamento de big data e que o Apache Spark deve ser executado no Kubernetes.
O maior benefício de usar o Spark no Kubernetes é que ele permite um dimensionamento muito mais fácil de aplicativos Spark. Isso ocorre porque o Kubernetes foi projetado para lidar com implantações de um grande número de contêineres simultâneos. Portanto, se você tiver um aplicativo Spark que precise processar muitos dados, basta implantar mais contêineres no cluster do Kubernetes para processar os dados em paralelo. Isso é muito mais fácil do que configurar um novo cluster do Spark no EMR sempre que você precisar aumentar a escala do processamento. Você pode executá-lo em qualquer plataforma de nuvem (AWS, Google Cloud, Azure, etc.) ou no local. Isso significa que você pode mover facilmente seus aplicativos Spark de um ambiente para outro sem ter que se preocupar em alterar seu gerenciador de cluster.
Outro grande benefício é que ele permite fluxos de trabalho mais flexíveis. Por exemplo, se você precisar processar dados de várias fontes, poderá implantar facilmente contêineres diferentes para cada fonte e processá-los em paralelo. Isso é muito mais fácil do que tentar gerenciar um fluxo de trabalho complexo em um único cluster do Spark.
O Kubernetes possui vários recursos de segurança que o tornam uma opção mais atraente para executar aplicativos Spark. Por exemplo, o Kubernetes dá suporte ao controle de acesso baseado em função, que permite ajustar quem tem acesso ao cluster do Spark.
Então aí está. Estas são apenas algumas das razões pelas quais acreditamos que o Apache Spark deve ser executado no Kubernetes. Se você não está convencido, recomendamos que experimente por si mesmo. Achamos que você ficará surpreso com o quão bem funciona.
Recursos adicionais
- Confira como instalar o Minikube
- Documentação do Kubernetes
- Site oficial da Ilum
- Documentação Oficial da Ilum
- Gráfico do Elmo de Ilum
Conclusão
O Ilum simplifica o processo de instalação e gerenciamento do Apache Spark no Kubernetes, tornando-o a escolha ideal para iniciantes e usuários experientes. Seguindo este guia, você terá um cluster Spark funcional em execução no Kubernetes rapidamente.