Implantando o microsserviço PySpark no Kubernetes: revolucionando data lakes com o Ilum.

Saudações, entusiastas do Ilum e fãs do Python! Estamos entusiasmados em revelar um novo recurso ansiosamente esperado que está definido para capacitar sua jornada de ciência de dados - suporte completo ao Python no Ilum. Para quem está no mundo dos dados, o Python e o Apache Spark são uma dupla icônica, lidando perfeitamente com grandes volumes de dados e cálculos complexos. E agora, com a atualização mais recente do Ilum, você pode aproveitar o poder do Python diretamente no seu ambiente de data lake favorito.
Esta postagem do blog é sua visita guiada para explorar esse recurso. Vamos começar com um trabalho simples do Apache Spark escrito em Python, executá-lo no Ilum e depois nos aprofundar. Transformaremos o código inicial para dar suporte a um modo interativo, oferecendo acesso direto ao trabalho do Spark por meio da API do Ilum. Ao final desta jornada, você terá um microsserviço baseado em Python respondendo a chamadas de API, tudo funcionando sem problemas no Ilum.
Então, você está pronto para aprimorar seu jogo de dados com Python e Ilum? Vamos começar.
Todos os exemplos estão disponíveis em nosso Repositório GitHub .
Etapa 1: Escrevendo um trabalho simples do Apache Spark em Python.
Antes de embarcarmos em nossa jornada Python com o Ilum, precisamos garantir que nosso ambiente esteja bem equipado. Para executar um trabalho do Spark, você precisa ter o Ilum e o PySpark instalados. Você pode usar pip, o instalador de pacotes do Python, para configurar o PySpark. Verifique se você está usando Python >=3.9.
pip instalar pyspark Para configurar e acessar o Ilum, siga as orientações fornecidas aqui .
1.1 Exemplo de SparkPi.
Agora, vamos mergulhar na escrita do nosso trabalho no Spark. Começaremos com um exemplo simples de SparkPi
importar sys
de importação aleatória aleatória
From operator import add
de pyspark.sql importar SparkSession
if __name__ == "__main__":
faísca = SparkSession \
.construtor\
.appName("PythonPi") \
.getOrCreate()
partições = int(sys.argv[1]) if len(sys.argv) > 1 else 2
n = 100000 * partições
def f(_: int) -> float:
x = aleatório() * 2 - 1
y = aleatório() * 2 - 1
return 1 if x ** 2 + y ** 2 <= 1 else 0
contagem = spark.sparkContext.parallelize(range(1, n + 1), partições).map(f).reduce(adicionar)
print("Pi é aproximadamente %f" % (4.0 * contagem / n))
spark.stop() Salve este script como ilum_python_simple.py
Com nosso trabalho do Spark pronto, é hora de executá-lo no Ilum. O Ilum oferece a capacidade de enviar trabalhos usando a interface do usuário do Ilum ou por meio da API REST.
Vamos começar com a interface do usuário com o recurso de trabalho único.
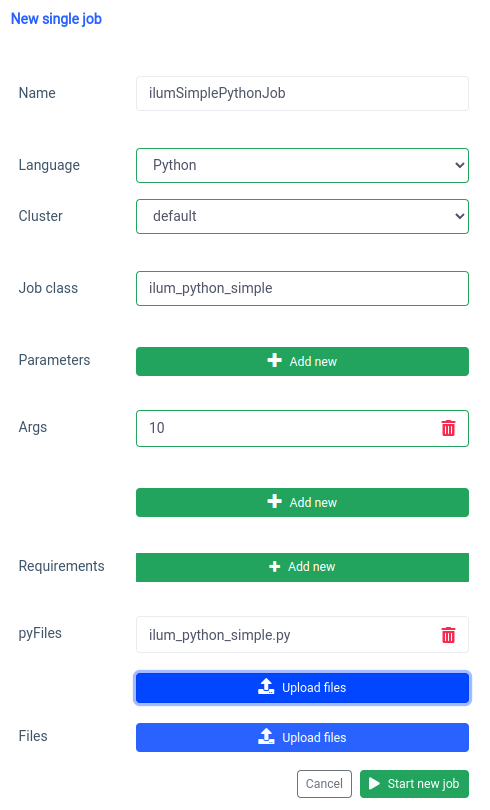
Podemos conseguir a mesma coisa com o API , mas primeiro, precisamos expor a API ilum-core com o encaminhamento de porta.
SVC/ILUM-CORE de encaminhamento de porta kubectl 9888:9888 Com a porta exposta, podemos fazer uma chamada de API.
curl -X POST 'localhost:9888/api/v1/job/submit' \
--form 'nome="ilumSimplePythonJob"' \
--form 'nome_do_cluster = "padrão"' \
--form 'jobClass="ilum_python_simple"' \
--form 'args="10"' \
--form 'pyFiles=@"/caminho/para/ilum_python_simple.py"' \
--form 'linguagem="PYTHON"' Chamada de API
Como resultado, receberemos o id do trabalho criado.
{"jobId":"20230724-1154-m78f3gmlo5j"} Resultado
Para verificar os logs do trabalho, podemos fazer uma chamada de API para
curl localhost:9888/api/v1/job/20230724-1154-m78f3gmlo5j/logs Chamada de API
E é isso! Você escreveu e executou um trabalho simples do Python Spark no Ilum. Vejamos um exemplo um pouco mais avançado que precisa de bibliotecas Python adicionais.
1.2 Exemplo de trabalho com numpy.
Nesta seção, veremos um exemplo prático de um trabalho do Spark escrito em Python. Esse trabalho envolve ler um conjunto de dados, processá-lo, treinar um modelo de aprendizado de máquina nele e salvar as previsões. Vamos usar um Tel-churn.csv arquivo, que você pode encontrar em nosso Repositório GitHub . Para facilitar as coisas, carregamos esse arquivo em um bucket chamado ilum-files na instância integrada do MinIO, que pode ser acessado automaticamente a partir da instância do Ilum. Isso significa que você não terá que se preocupar em configurar nenhum acesso para este exemplo - a Ilum tem tudo o que você precisa. No entanto, se você quiser buscar dados de um bucket diferente ou usar o Amazon S3 em seus próprios projetos, precisará configurar os acessos de acordo.
Agora que temos nossos dados prontos, vamos começar a escrever nosso trabalho do Spark em Python. Aqui está o exemplo de código completo:
de pyspark.sql importar SparkSession
do pipeline de importação de pyspark.ml
de pyspark.ml.feature import StringIndexer, VectorAssembler
de pyspark.ml.classification import LogisticRegression
if __name__ == "__main__":
faísca = SparkSession \
.construtor\
.appName("IlumAdvancedPythonExample") \
.getOrCreate()
df = spark.read.csv('s3a://ilum-files/Tel-churn.csv', header=True, inferSchema=True)
categoricalColumns = ['gênero', 'Parceiro', 'Dependentes', 'PhoneService', 'MultipleLines', 'InternetService',
'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV',
'StreamingMovies', 'Contrato', 'PaperlessBilling', 'PaymentMethod']
estágios = []
for categoricalCol em categoricalColumns:
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Índice")
estágios += [stringIndexer]
label_stringIdx = StringIndexer(inputCol="Churn", outputCol="label")
estágios += [label_stringIdx]
numericCols = ['Idoso', 'posse', 'CobrançasMensais']
assemblerInputs = [c + "Índice" para c em categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
estágios += [assembler]
pipeline = Pipeline(stages=stages)
pipelineModel = pipeline.fit(df)
df = pipelineModel.transform(df)
treinar, teste = df.randomSplit([0,7, 0,3], semente=42)
lr = LogisticRegression(featuresCol="features", labelCol="label", maxIter=10)
lrModel = lr.fit(trem)
previsões = lrModel.transform(teste)
predictions.select("ID do cliente", "rótulo", "previsão").show(5)
predictions.select("códigoDocliente", "rótulo", "previsão").write.option("cabeçalho", "true") \
.csv('s3a://ilum-files/predictions')
spark.stop() Vamos mergulhar no código:
de pyspark.sql importar SparkSession
do pipeline de importação de pyspark.ml
de pyspark.ml.feature import StringIndexer, VectorAssembler
de pyspark.ml.classification import LogisticRegression Aqui, estamos importando os módulos PySpark necessários para criar uma sessão do Spark, criar um pipeline de aprendizado de máquina, pré-processar os dados e executar um modelo de regressão logística.
faísca = SparkSession \
.construtor\
.appName("IlumAdvancedPythonExample") \
.getOrCreate() Inicializamos um Sessão do SparkSession , que é o ponto de entrada para qualquer funcionalidade no Spark. É aqui que definimos o nome do aplicativo que aparecerá na interface do usuário da Web do Spark.
df = spark.read.csv('s3a://ilum-files/Tel-churn.csv', header=True, inferSchema=True) Estamos lendo um arquivo CSV armazenado em um bucket minio. O header=Verdadeiro informa ao Spark para usar a primeira linha do arquivo CSV como cabeçalhos, enquanto inferSchema=Verdadeiro faz com que o Spark determine automaticamente o tipo de dados de cada coluna.
categoricalColumns = ['gênero', 'Parceiro', 'Dependentes', 'PhoneService', 'MultipleLines', 'InternetService',
'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV',
'StreamingMovies', 'Contrato', 'PaperlessBilling', 'PaymentMethod'] Especificamos as colunas em nossos dados que são categóricas. Eles serão transformados posteriormente usando um StringIndexer.
estágios = []
for categoricalCol em categoricalColumns:
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Índice")
estágios += [stringIndexer] Aqui, estamos iterando em nossa lista de colunas categóricas e criando um StringIndexer para cada uma. StringIndexers codificam colunas de cadeia de caracteres categóricas em uma coluna de índices. A coluna de índice transformada será nomeada como o nome da coluna original anexado com "Índice".
numericCols = ['Idoso', 'posse', 'CobrançasMensais']
assemblerInputs = [c + "Índice" para c em categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
estágios += [assembler] Aqui, preparamos os dados para nosso modelo de aprendizado de máquina. Criamos um VectorAssembler que pegará todas as nossas colunas de recursos (categóricas e numéricas) e as montará em uma única coluna vetorial. Esse é um requisito para a maioria dos algoritmos de aprendizado de máquina no Spark.
treinar, teste = df.randomSplit([0,7, 0,3], semente=42) Dividimos nossos dados em um conjunto de treinamento e um conjunto de teste, com 70% dos dados para treinamento e os 30% restantes para teste.
lr = LogisticRegression(featuresCol="features", labelCol="label", maxIter=10)
lrModel = lr.fit(trem) Treinamos um modelo de regressão logística em nossos dados de treinamento.
previsões = lrModel.transform(teste)
predictions.select("ID do cliente", "rótulo", "previsão").show(5)
predictions.select("códigoDocliente", "rótulo", "previsão").write.option("cabeçalho", "true") \
.csv('s3a://ilum-files/predictions') Por fim, usamos nosso modelo treinado para fazer previsões em nosso conjunto de testes, exibindo as 5 primeiras previsões. Em seguida, escrevemos essas previsões de volta em nosso minio bucket.
Salve este script como ilum_python_advanced.py
pyspark.ml usa numpy como uma dependência que não está instalada como padrão, portanto, precisamos especificá-la como um requisito.
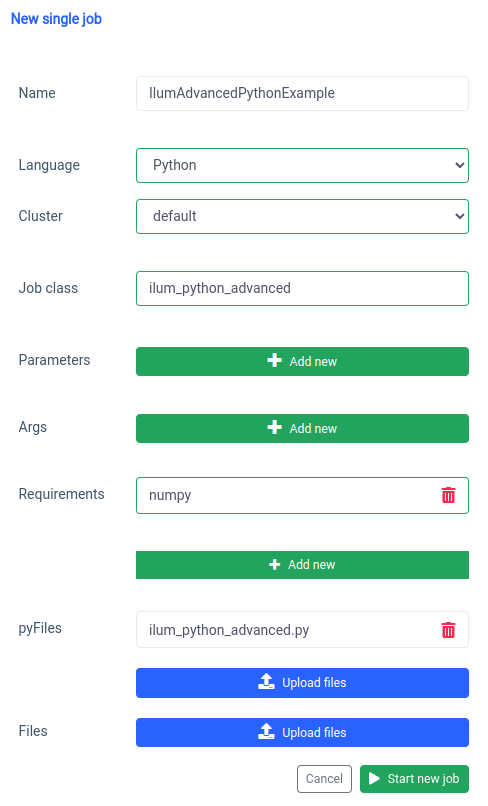
E a mesma coisa pode ser feita por meio da API.
curl -X POST 'localhost:9888/api/v1/job/submit' \
--form 'name="IlumAdvancedPythonExample"' \
--form 'nome_do_cluster = "padrão"' \
--form 'jobClass="ilum_python_advanced"' \
--form 'pyRequirements="numpy"' \
--form 'pyFiles=@"/caminho/para/ilum_python_advanced.py"' \
--form 'linguagem="PYTHON"' Chamada de API
Nas próximas seções, transformaremos os dois scripts Python em um interativo Spark job, aproveitando ao máximo as capacidades de Ilum.
Etapa 2: Transição para o modo interativo
O modo interativo é um recurso interessante que torna o desenvolvimento do Spark mais dinâmico, oferecendo a capacidade de executar, interagir e controlar seus trabalhos do Spark em tempo real. Ele foi projetado para aqueles que buscam um controle mais direto sobre seus aplicativos Spark.
Pense no modo interativo como ter uma conversa direta com seu trabalho do Spark. Você pode alimentar dados, solicitar transformações e buscar resultados - tudo em tempo real. Isso aumenta drasticamente a agilidade e a capacidade do seu pipeline de processamento de dados, tornando-o mais adaptável e responsivo às mudanças nos requisitos.
Agora que estamos familiarizados com a criação de um trabalho básico do Spark em Python, vamos dar um passo adiante, transformando nosso trabalho em um trabalho interativo que pode aproveitar os recursos em tempo real do Ilum.
2.1 Exemplo de SparkPi.
Para ilustrar como fazer a transição de nosso trabalho para o modo Interativo, ajustaremos nosso ilum_python_simple.py roteiro.
de importação aleatória aleatória
From operator import add
de ilum.api import IlumJob
classe SparkPiInteractiveExample(IlumJob):
def run(self, spark, config):
partições = int(config.get('partições', '5'))
n = 100000 * partições
def f(_: int) -> float:
x = aleatório() * 2 - 1
y = aleatório() * 2 - 1
return 1 if x ** 2 + y ** 2 <= 1 else 0
contagem = spark.sparkContext.parallelize(range(1, n + 1), partições).map(f).reduce(adicionar)
return "Pi é aproximadamente %f" % (4,0 * contagem / n) Salve isso como ilum_python_simple_interactive.py
Existem apenas algumas diferenças em relação ao SparkPi original.
1. Pacote Ilum
Para começar, importamos o Trabalho de IlumJob class do pacote ilum, que serve como uma classe base para nosso trabalho interativo.
A lógica de trabalho do Spark é encapsulada em uma classe que estende Trabalho de IlumJob , nomeadamente no âmbito da sua correr método. Podemos adicionar o pacote ilum com:
pip instalar ilum 2. Spark job em uma classe
A lógica de trabalho do Spark é encapsulada em uma classe que estende Trabalho de IlumJob , nomeadamente no âmbito da sua correr método.
classe SparkPiInteractiveExample(IlumJob):
def run(self, spark, config):
# Lógica de trabalho aqui Envolver a lógica do trabalho em uma classe é essencial para que a estrutura do Ilum lide com o trabalho e seus recursos. Isso também torna o trabalho sem estado e reutilizável.
3. Os parâmetros são tratados de forma diferente:
Estamos pegando todos os argumentos do dicionário de configuração
partições = int(config.get('partições', '5')) Essa mudança permite uma passagem de parâmetros mais dinâmica e se integra ao tratamento de configuração do Ilum.
4. O resultado é retornado em vez de impresso:
O resultado é retornado do correr método.
return "Pi é aproximadamente %f" % (4,0 * contagem / n) Ao retornar o resultado, a Ilum pode lidar com isso de maneira mais flexível. Por exemplo, a Ilum poderia serializar o resultado e torná-lo acessível por meio de uma chamada de API.
5. Não há necessidade de gerenciar manualmente a sessão do Spark
A Ilum gerencia a sessão do Spark para nós. Ele é injetado automaticamente no correr e não precisamos pará-lo manualmente.
def run(self, spark, config): Essas alterações destacam a transição de um trabalho autônomo do Spark para um trabalho interativo do Ilum. O objetivo é melhorar a flexibilidade e a reutilização do trabalho, tornando-o mais adequado para cálculos dinâmicos, interativos e dinâmicos.
A adição de um trabalho interativo do Spark é tratada com a função 'novo grupo'.
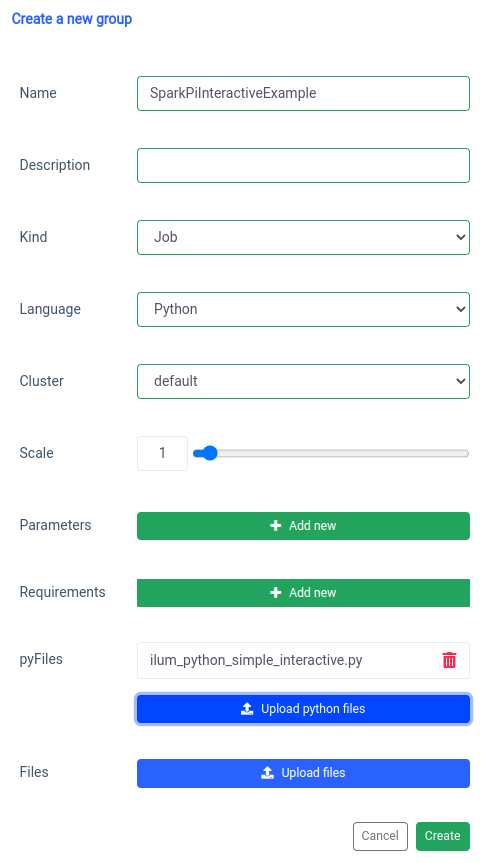
E a execução com a função de trabalho interativa na interface do usuário.
O nome da classe deve ser especificado como um pythonFileName.PythonClassImplementingIlumJob
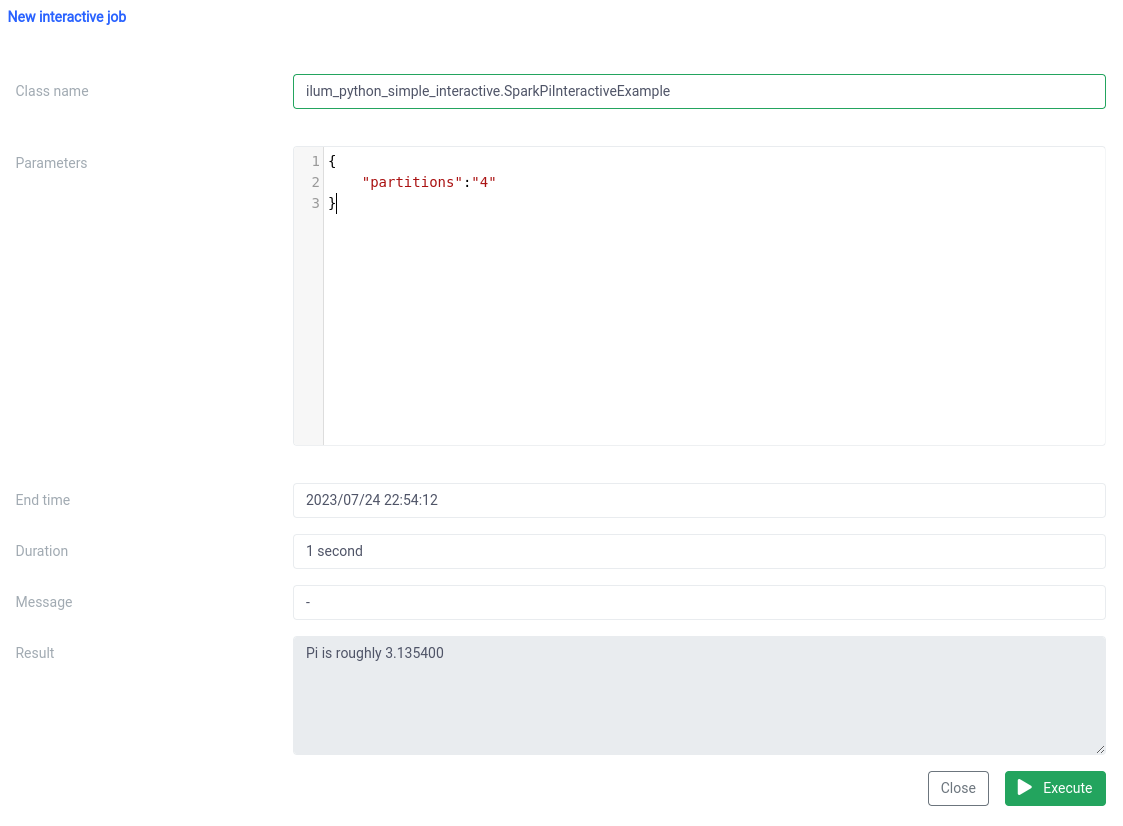
Podemos conseguir a mesma coisa com o API .
1. Criando grupo
curl -X POST 'localhost:9888/api/v1/group' \
--form 'name="SparkPiInteractiveExample"' \
--form 'kind="JOB"' \
--form 'nome_do_cluster = "padrão"' \
--form 'pyFiles=@"/caminho/para/ilum_python_simple_interactive.py"' \
--form 'linguagem="PYTHON"' Chamada de API
{"groupId":"20230726-1638-mjrw3"} Resultado
2. Execução do trabalho
curl -X POST 'localhost:9888/api/v1/group/20230726-1638-mjrw3/job/execute' \
-h 'Tipo de conteúdo: application/json' \
-d '{ "jobClass":"ilum_python_simple_interactive. SparkPiInteractiveExample", "jobConfig": {"partitions":"10"}, "type":"interactive_job_execute"}' Chamada de API
{
"jobInstanceId":"20230726-1638-mjrw3-a1srahhu",
"jobId":"20230726-1638-mjrw3-wwt5a",
"groupId":"20230726-1638-mjrw3",
"startTime":1690390323154,
"endTime":1690390325200,
"jobClass":"ilum_python_simple_interactive. SparkPiInteractiveExample",
"jobConfig":{
"partições":"10"
},
"result":"Pi é aproximadamente 3,149400",
"erro":null
} Resultado
2.2 Exemplo de trabalho com numpy.
Vejamos nosso segundo exemplo.
de pyspark.sql importar SparkSession
do pipeline de importação de pyspark.ml
de pyspark.ml.feature import StringIndexer, VectorAssembler
de pyspark.ml.classification import LogisticRegression
de ilum.api import IlumJob
class LogisticRegressionJobExample(IlumJob):
def run(self, spark_session: SparkSession, config: dict) -> str:
df = spark_session.read.csv(config.get('inputFilePath', 's3a://ilum-files/Tel-churn.csv'), header=True,
inferSchema=True)
categoricalColumns = ['gênero', 'Parceiro', 'Dependentes', 'PhoneService', 'MultipleLines', 'InternetService',
'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV',
'StreamingMovies', 'Contrato', 'PaperlessBilling', 'PaymentMethod']
estágios = []
for categoricalCol em categoricalColumns:
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Índice")
estágios += [stringIndexer]
label_stringIdx = StringIndexer(inputCol="Churn", outputCol="label")
estágios += [label_stringIdx]
numericCols = ['Idoso', 'posse', 'CobrançasMensais']
assemblerInputs = [c + "Índice" para c em categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
estágios += [assembler]
pipeline = Pipeline(stages=stages)
pipelineModel = pipeline.fit(df)
df = pipelineModel.transform(df)
train, test = df.randomSplit([float(config.get('splitX', '0.7')), float(config.get('splitY', '0.3'))],
seed=int(config.get('seed', '42')))
lr = LogisticRegression(featuresCol="features", labelCol="label", maxIter=int(config.get('maxIter', '5')))
lrModel = lr.fit(trem)
previsões = lrModel.transform(teste)
return '{}'.format(predictions.select("customerID", "label", "prediction").limit(
int(config.get('rowLimit', '5'))).toJSON().collect()) 1. Encapsulamos o trabalho em uma classe, assim como no exemplo anterior:
class LogisticRegressionJobExample(IlumJob):
def run(self, spark_session: SparkSession, config: dict) -> str:
# Lógica de trabalho aqui Novamente, a lógica do trabalho é encapsulada no correr método de uma classe que estende Trabalho de IlumJob , ajudando a Ilum a lidar com o trabalho de forma eficiente.
2. Todos os parâmetros, incluindo aqueles para o pipeline de dados (como caminhos de arquivo e hiperparâmetros de regressão logística), são obtidos do configuração dicionário:
df = spark_session.read.csv(config.get('inputFilePath', 's3a://ilum-files/Tel-churn.csv'), header=True, inferSchema=True)
train, test = df.randomSplit([float(config.get('splitX', '0.7')), float(config.get('splitY', '0.3'))], seed=int(config.get('seed', '42')))
lr = LogisticRegression(featuresCol="features", labelCol="label", maxIter=int(config.get('maxIter', '5'))) Ao centralizar todos os parâmetros em um só lugar, o Ilum fornece uma maneira uniforme e consistente de configurar e ajustar o trabalho.
O resultado do trabalho, em vez de ser gravado em um local específico, é retornado como uma string JSON:
return '{}'.format(predictions.select("customerID", "label", "prediction").limit(int(config.get('rowLimit', '5'))).toJSON().collect()) Isso permite um tratamento mais dinâmico e flexível do resultado do trabalho, que pode ser processado posteriormente ou exposto por meio de uma API, dependendo das necessidades do aplicativo.
Este código mostra perfeitamente como podemos integrar perfeitamente os trabalhos do PySpark com o Ilum para permitir pipelines de processamento de dados interativos e orientados por API. De exemplos simples, como aproximação de Pi, a casos mais complexos, como regressão logística, os trabalhos interativos do Ilum são versáteis, adaptáveis e eficientes.
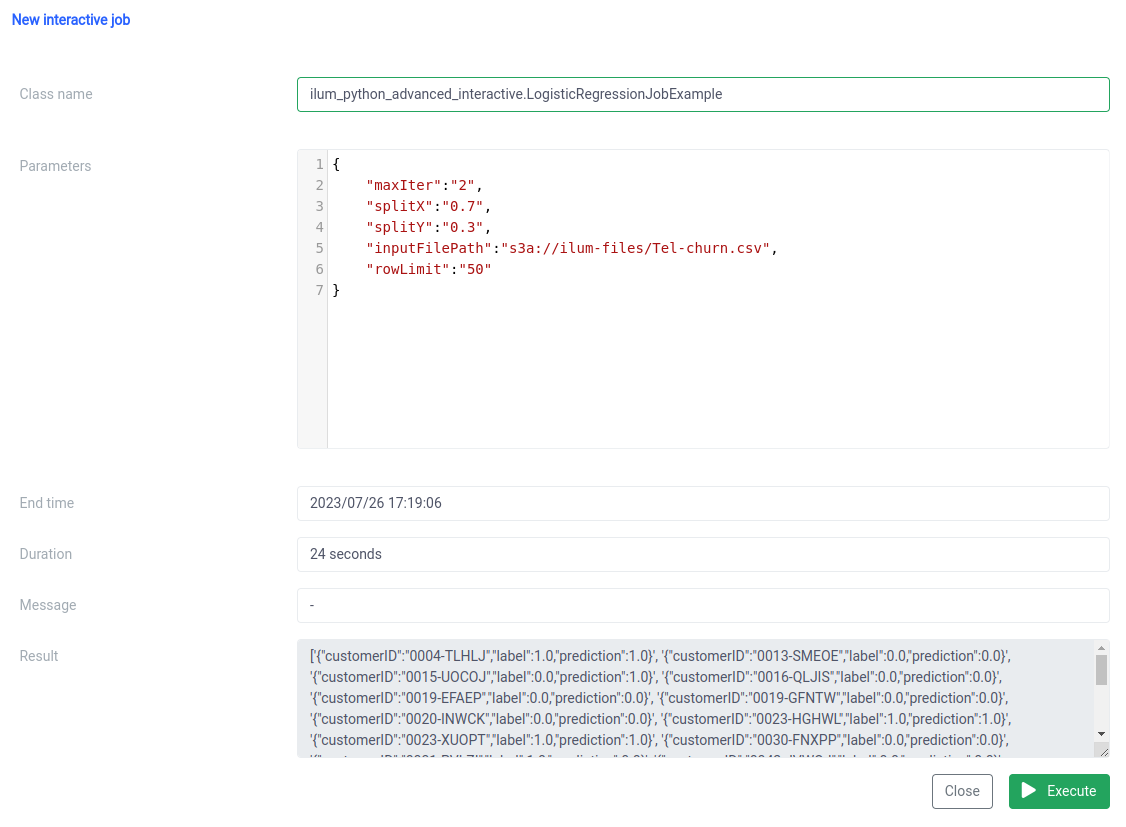
Etapa 3: Tornar seu trabalho do Spark um microsserviço
Os microsserviços trazem uma mudança de paradigma da estrutura tradicional de aplicativos monolíticos para uma abordagem mais modular e ágil. Ao dividir um aplicativo complexo em serviços pequenos e fracamente acoplados, fica mais fácil criar, manter e dimensionar cada serviço de forma independente com base em requisitos específicos. Quando aplicado ao nosso trabalho do Spark, isso significa que podemos criar um serviço de processamento de dados robusto que pode ser dimensionado, gerenciado e atualizado sem afetar outras partes de nossa pilha de aplicativos.
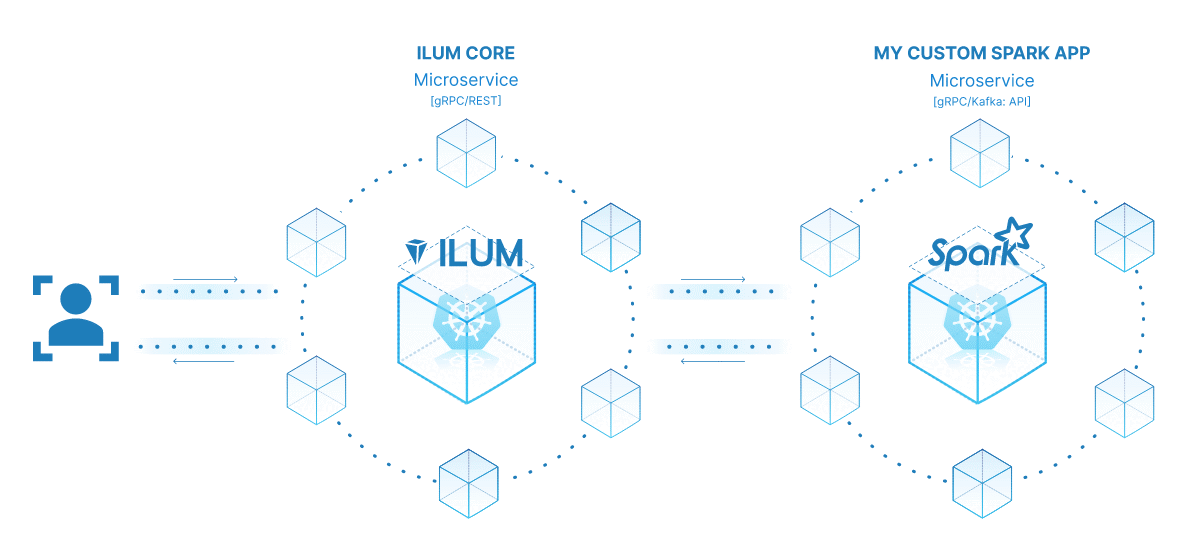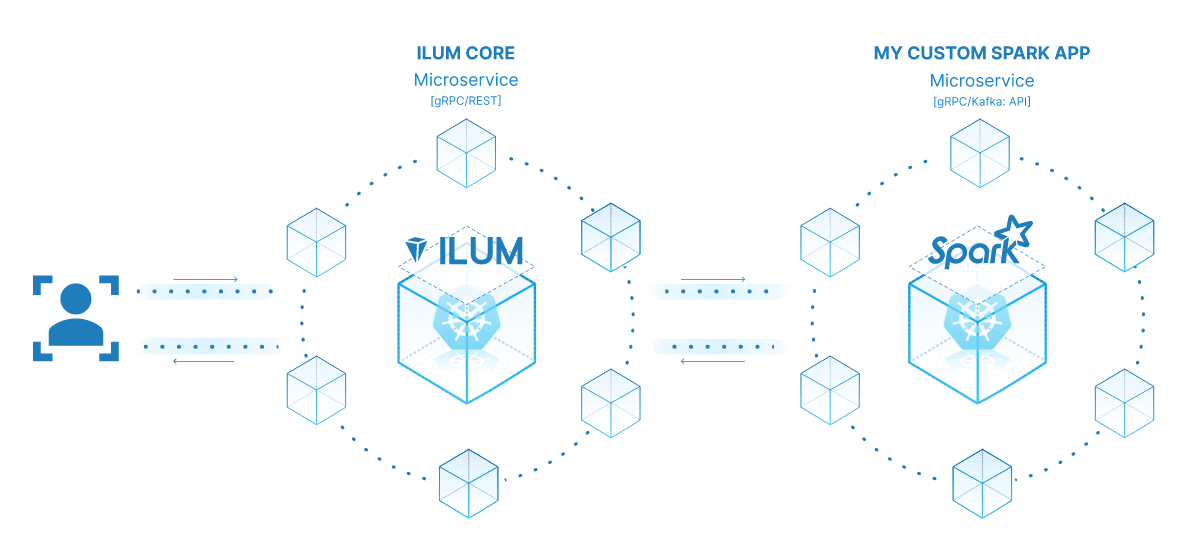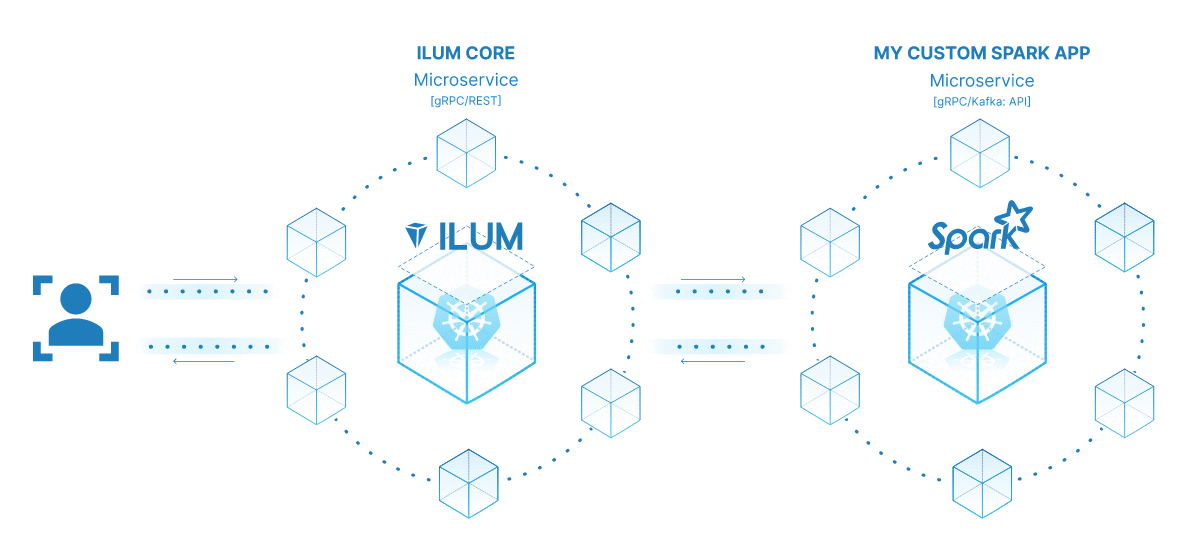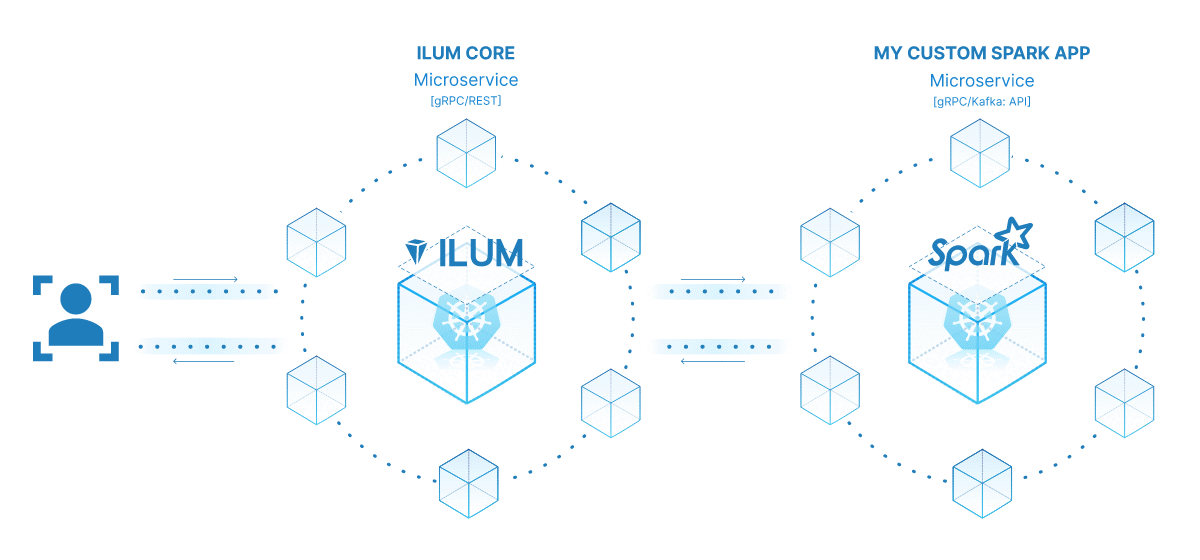
O poder de transformar seu trabalho do Spark em um microsserviço está em sua versatilidade, escalabilidade e recursos de interação em tempo real. Um microsserviço é um componente implantável de forma independente de um aplicativo que é executado como um processo separado. Ele se comunica com outros componentes por meio de APIs bem definidas, dando a você a liberdade de projetar, desenvolver, implantar e dimensionar cada microsserviço de forma independente.
No contexto do Ilum, um trabalho interativo do Spark pode ser tratado como um microsserviço. O método 'run' do job atua como um endpoint de API. Cada vez que você chama esse método por meio da API do Ilum, você está fazendo uma solicitação para esse microsserviço. Isso abre o potencial para interações em tempo real com seu trabalho do Spark.
Você pode fazer solicitações para seu microsserviço de vários aplicativos ou scripts, buscando dados e processando resultados em tempo real. Além disso, abre uma oportunidade para criar arquiteturas mais complexas e orientadas a serviços em torno de seus pipelines de processamento de dados.
Uma das principais vantagens dessa configuração é a escalabilidade. Por meio da interface do usuário ou API do Ilum, você pode aumentar ou diminuir seu trabalho (microsserviço) com base na carga ou na complexidade computacional. Você não precisa se preocupar com o gerenciamento manual de recursos ou balanceamento de carga. O balanceador de carga interno do Ilum distribuirá chamadas de API entre instâncias do seu trabalho do Spark, garantindo a utilização eficiente de recursos.
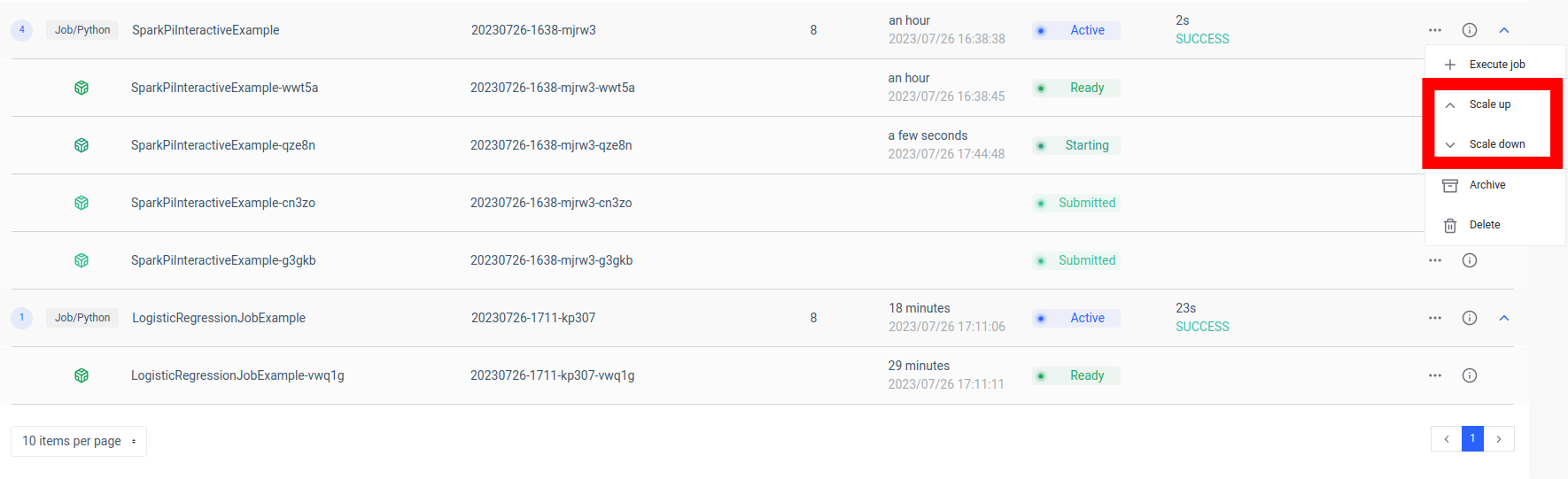
Lembre-se de que o tempo real de processamento do trabalho depende da complexidade do trabalho do Spark e dos recursos alocados a ele. No entanto, com a escalabilidade fornecida pelo Kubernetes, você pode escalar facilmente seus recursos à medida que os requisitos do seu trabalho aumentam.
Essa combinação de Ilum, Apache Spark e microsserviços traz uma maneira nova e ágil de processar seus dados - de forma eficiente, escalável e responsiva!

O divisor de águas na arquitetura de microsserviços de dados
Percorremos um longo caminho desde que começamos essa jornada de transformar um trabalho simples do Python Apache Spark em um microsserviço completo usando o Ilum. Vimos como era fácil escrever um trabalho do Spark, adaptá-lo para funcionar no modo interativo e, por fim, expô-lo como um microsserviço com a ajuda da API robusta do Ilum. Ao longo do caminho, aproveitamos o poder do Python, os recursos do Apache Spark e a flexibilidade e escalabilidade do Ilum. Essa combinação não apenas transformou nossos recursos de processamento de dados, mas também mudou a maneira como pensamos sobre a arquitetura de dados.
A jornada não para por aqui. Com suporte total ao Python no Ilum, um novo mundo de possibilidades se abre para processamento e análise de dados. À medida que continuamos a construir e melhorar o Ilum, estamos entusiasmados com as possibilidades futuras que o Python traz para nossa plataforma. Acreditamos que, com o Python e o Ilum juntos, estamos apenas no início da redefinição do que é possível no mundo da arquitetura de microsserviços de dados.
Junte-se a nós nesta emocionante jornada e vamos moldar o futuro do processamento de dados juntos!