Running Jupyter on Kubernetes with Spark (and Why Ilum Makes It Easy)

If you’ve done data science long enough, you’ve met this moment: you open a Jupyter notebook, hit Shift+Enter, and the cell just… hangs. Somewhere a Spark driver is starved for memory, or a cluster is “almost” configured, or the library versions don’t quite agree. You’re here to explore data, not babysit infrastructure.
That’s where Kubernetes shines and where Ilum , a free, cloud-native data lakehouse focused on running and monitoring Apache Spark on Kubernetes, helps you go from “why is this stuck?” to “let’s try that model” with far less friction.
In this post, we’ll take a narrative walk from a clean laptop to a working Jupyter e Apache Zeppelin setup on Kubernetes , both backed by Apache Spark and connected through a Livy-compatible API. You’ll see how Ilum plugs into the picture, why it matters for day-to-day data work, and how to scale from a single demo box to a real cluster without rewriting your notebooks.
Why Kubernetes for Data Science
Kubernetes (K8s) gives you three things notebooks secretly crave:
- Elasticity: Executors scale up when a join explodes, and back down when you’re idle.
- Isolation: Each user or team runs in a clean, containerized environment—no shared-conda-env roulette.
- Repeatability: “It works on my machine” becomes “it works because it’s declarative.”
Pair K8s with Fagulha and a notebook front-end, and you get an interactive analytics platform that grows with your data. Pair it with Ilum , and you also get the plumbing and observability—logs and metrics—that keep you moving when things go sideways.
The missing piece: speaking Livy
Both Jupyter (via Sparkmagic)e Zeppelin (via its Livy interpreter) speak the Livy REST API to manage Spark sessions. Ilum implements that API through an embedded proxy de lívio , so your notebooks can create and use Spark sessions while Ilum handles the Spark-on-K8s lifecycle behind the scenes.
Think of it this way:
Notebook → Livy API → Ilum → Spark on Kubernetes
You write cells. Ilum speaks Kubernetes. Spark does the heavy lifting.
No special notebook rewrites, no custom glue.
A gentle, from-scratch run-through
Let’s build a tiny playground locally with Minikube . Later, you can point the exact same setup at GKE/EKS/AKS or prem k8s distro.
1) Start a small Kubernetes cluster
You don’t need production horsepower to try this—just a few CPUs and memory.
minikube start --cpus 6 --memory 12288 --addons metrics-server
kubectl get nodesYou’ll see a node and the metrics add-on come up. That’s enough to host Spark drivers and executors for a demo.
2) Install Ilum with Jupyter, Zeppelin, and the Livy proxy
Ilum ships Helm charts so you don’t have to handcraft manifests.
helm repo add ilum https://charts.ilum.cloud
helm repo update
helm install ilum ilum/ilum \
--set ilum-zeppelin.enabled=true \
--set ilum-jupyter.enabled=true \
--set ilum-livy-proxy.enabled=true
kubectl get pods -wGrab a coffee while pods settle. When the dust clears, you have Ilum’s core plus bundled Jupyter e Zepelim ready to talk to Spark through the Livy-compatible proxy.
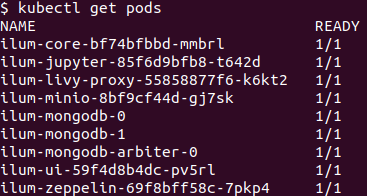
Accessing the Ilum UI after installation
a) Port-forward (quick local access)
SVC/ILUM-UI de encaminhamento de porta kubectl 9777:9777 Open: http://localhost:9777
b) NodePort (stable for testing)
For testing, a Porta de nó is enabled by default (avoids port-forward drops).
Open: http://<KUBERNETES_NODE_IP>:31777
Ponta: Get the node IP with kubectl obter nós -o wide (ou minikube ip on Minikube).
c) Minikube shortcut
Serviço Minikube ILUM-UI This opens the service in your browser (or prints the URL) using your Minikube IP.
d) Production
Use an Ingress (TLS, domain, auth). See: https://ilum.cloud/docs/configuration/ilum-ui/#ilum-ui-ingress-parameters
First contact: Jupyter + Sparkmagic (via Ilum UI)
Open the Ilum UI in your browser. From the left navigation bar, go to Notebooks .

In Jupyter:
- Crie um Python 3 notebook.
- Load Sparkmagic:
%load_ext sparkmagic.magics - Open the spark session manager
%manage_spark 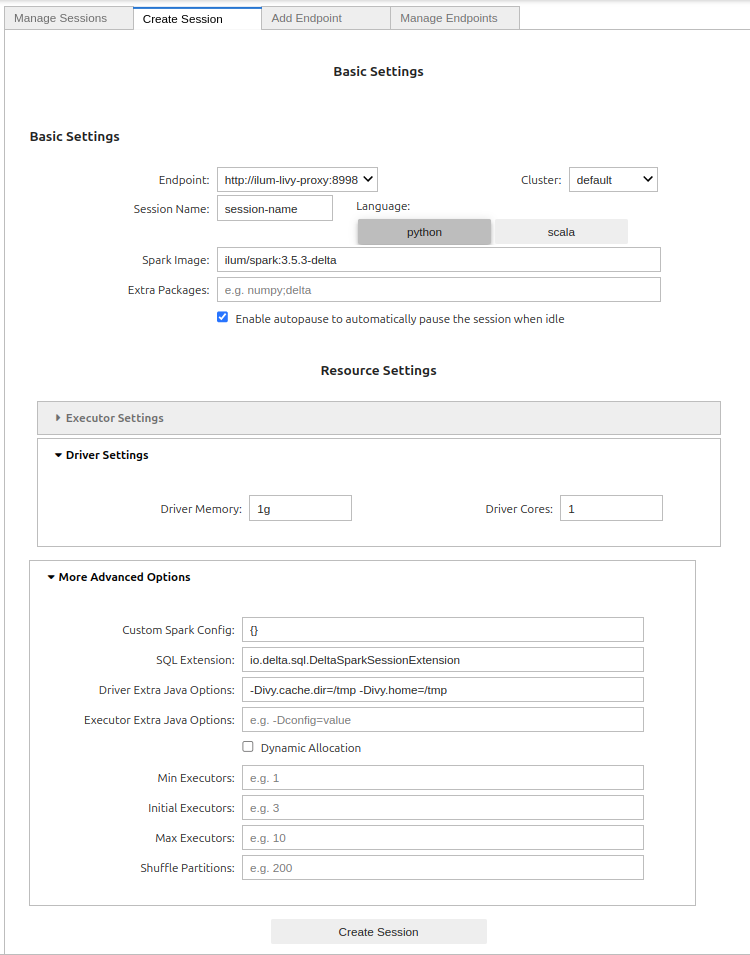
Basic Settings
- Endpoint – Select the preconfigured Livy endpoint (usually
http://ilum-livy-proxy:8998). This is how Jupyter/Sparkmagic talks to Ilum. - Cluster – Choose the target cluster (e.g.,
inadimplência). If you manage multiple K8s clusters in Ilum, pick the one you want your driver/executors to run on. - Session Name – Any short identifier (e.g.,
eda-january). You’ll see this in Sparkmagic session lists. - Idioma –
python(PySpark) orscala. Most Jupyter users go with Python. - Spark Image – The container image for your Spark driver/executors (e.g.,
ilum / faísca: 3.5.3-delta). Images tagged with-deltaalready include Delta Lake. - Extra Packages – Comma-separated extras to pull into the session (e.g.,
numpy,delta).- Tip: if you selected a
-deltaimage, you usually don’t need to adddeltaagain.
- Tip: if you selected a
- Enable autopause – When checked, Ilum will automatically pause the session after it’s idle for a while to save resources. You can resume it from the UI.
Resource Settings
- Driver Settings
- Driver Memory – Start with
1 ourofor demos; bump to2–4gfor heavier notebooks. - Driver Cores –
1is fine for exploratory work; increase if your driver does more coordination/collects.
- Driver Memory – Start with
- Executor Settings (collapsed by default)
- Configure only if you want to override defaults; many users rely on dynamic allocation (below).
More Advanced Options
- Custom Spark Config – JSON map for
spark.*keys (e.g., event logs, S3 creds, serializer). Example:jsonCopyEdit{
"spark.eventLog.enabled": "true",
"spark.sql.adaptive.enabled": "true"
} - SQL Extension – Pre-fills for Delta Lake:
io.delta.sql.DeltaSparkSessionExtension. Leave as-is if you plan to read/write Delta tables. - Driver Extra Java Options – JVM flags for the driver. The defaults (
-Divy.cache.dir=/tmp -Divy.home=/tmp) keep Ivy dependency caches inside the container. - Executor Extra Java Options – Same idea, but for executors. Leave empty unless you need specific JVM flags.
- Dynamic Allocation – Let Spark scale executors automatically.
- Min Executors – Floor for scaling (e.g.,
1). - Initial Executors – Startup size (e.g.,
2–3). - Max Executors – Ceiling (e.g.,
10for demos, higher in prod).
- Min Executors – Floor for scaling (e.g.,
- Shuffle Partitions – Number of partitions for wide ops (e.g.,
200). Rule of thumb: start near 2–3× total executor cores, then tune.
Clique Create Session. Ilum will start the Spark driver and executors on Kubernetes; the first pull can take a minute if images are new. When the status flips to available, you’re ready to run cells:

%%spark
spark.range(0, 100000).selectExpr("count(*) as n").show()%%spark
from pyspark.sql import Row
rows = [Row(id=1, city="Warsaw"), Row(id=2, city="Riyadh"), Row(id=3, city="Austin")]
print(rows)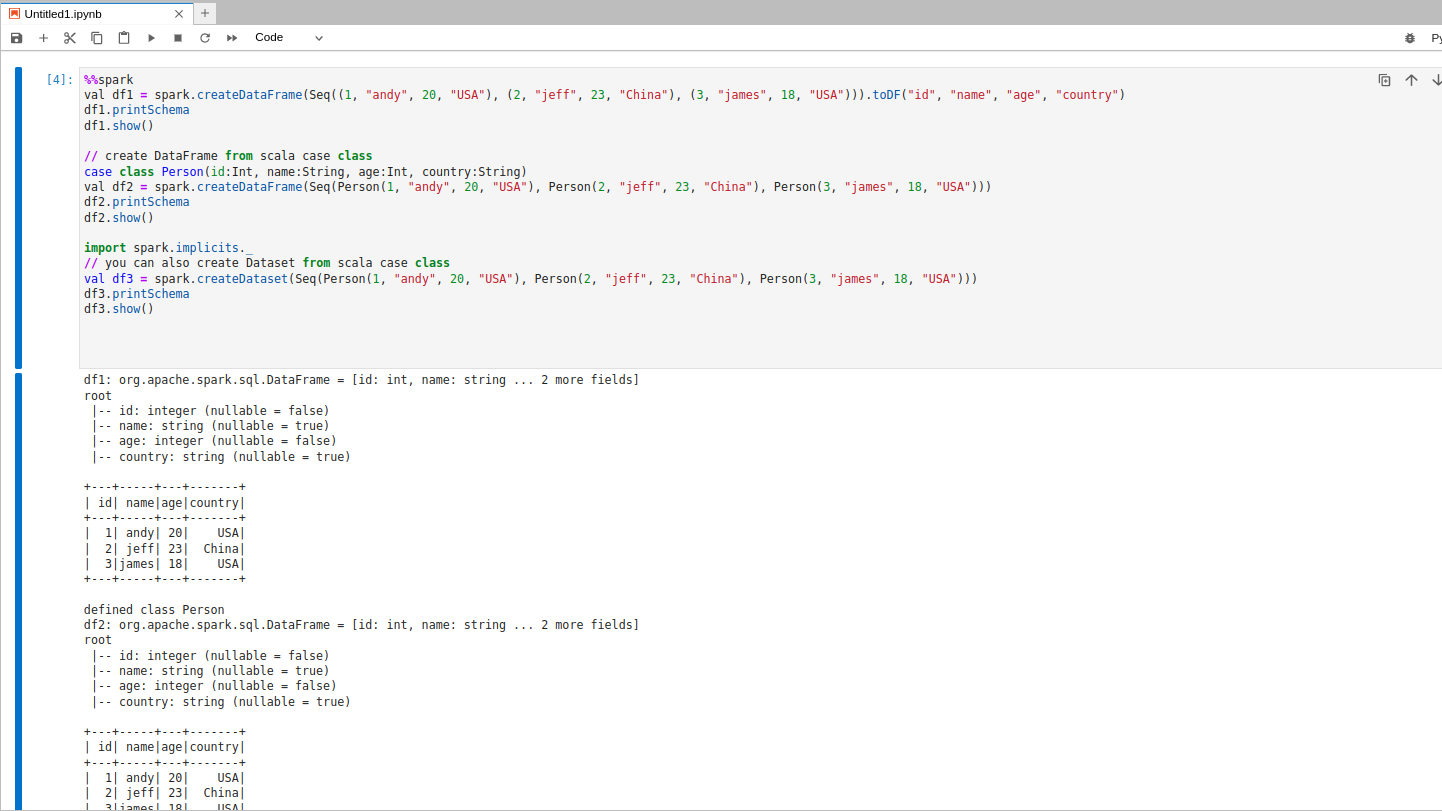
It’s a small example, but the important part is what just happened: Jupyter spoke Livy. Ilum created a Spark session on Kubernetes, Spark did the work. You didn’t touch a single YAML by hand.
Or if you prefer: Apache Zeppelin
Some teams love Zeppelin for its multi-language paragraphs and shareable notes. That works here too.
- Para executar o código, precisamos criar uma nota:
2. Como a comunicação com o Ilum é tratada via livy-proxy, precisamos escolher o livy como interpretador padrão.
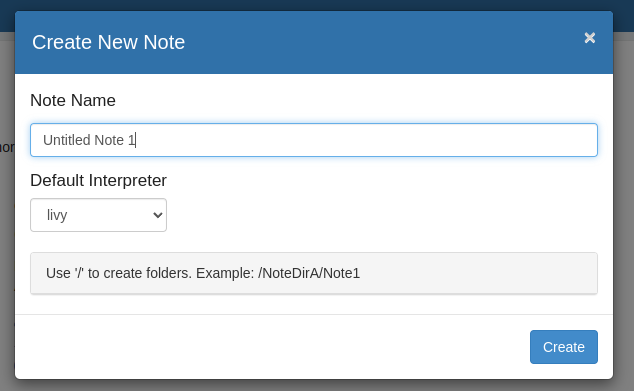
3. Agora vamos abrir a nota e colocar algum código no parágrafo:
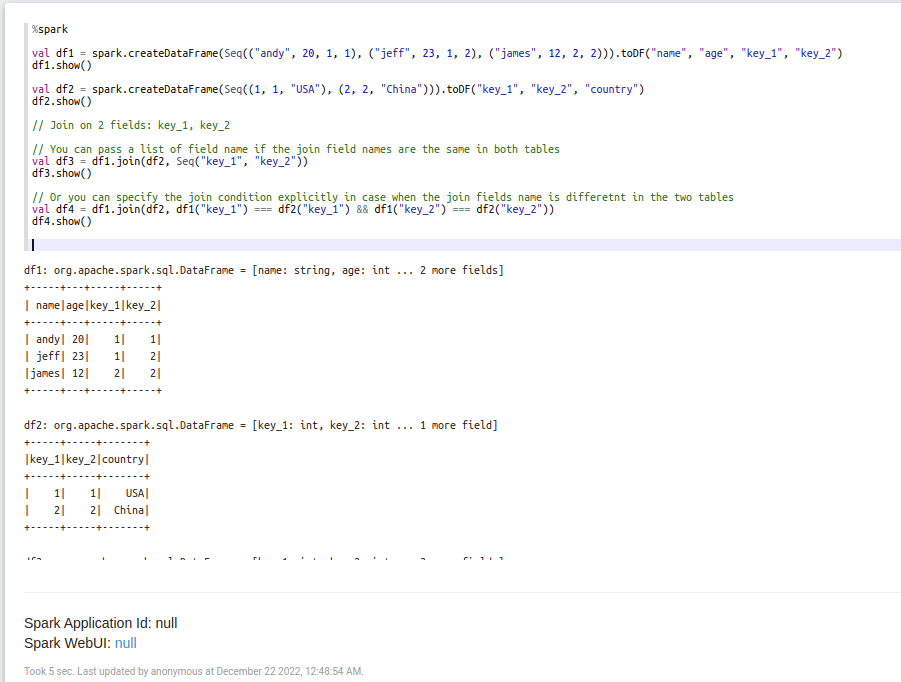
O mesmo para o Jupyter, o Zeppelin também tem uma configuração predefinida que é necessária para o Ilum. Você pode personalizar as configurações facilmente. Basta abrir o menu de contexto no canto superior direito e clicar no botão do intérprete.
Há uma longa lista de intérpretes e suas propriedades que podem ser personalizadas.
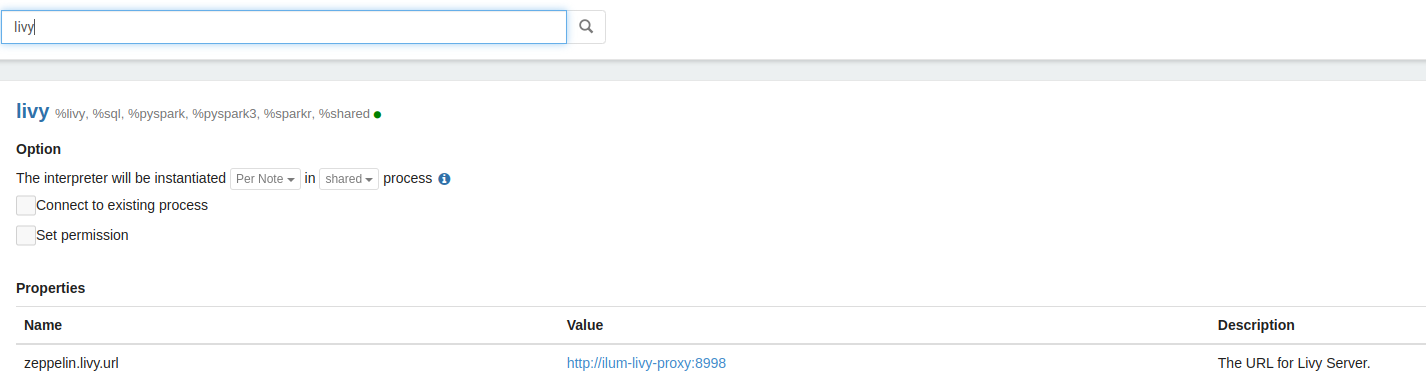
O Zeppelin fornece 3 modos diferentes para executar o processo do interpretador: compartilhado, com escopo e isolado. Você pode saber mais sobre o modo de vinculação do intérprete aqui .
Same experience: Zeppelin sends code through Livy. Ilum spins up and manages the session on K8s. Spark runs it.
A quick detour into production thinking (without killing the vibe)
Here are the ideas you’ll care about when this graduates from demo to team-wide platform:
- Armazenamento : For a lakehouse, use object storage (S3/MinIO/GCS/Azure Blob). Keep Spark event logs there so the Servidor de Histórico can give you post-mortems that aren’t just vibes.
- Segurança : Put Jupyter/Zeppelin behind SSO (OIDC/Keycloak), scope access with Kubernetes RBAC, and keep secrets in a manager, not in a notebook cell.
- Autoscaling: Let the cluster scale node pools; let Spark dynamic allocation manage executors. Your wallet and your patience will thank you.
- Costs: Spot/preemptible nodes for executors, right-size memory/cores, and avoid tiny files (Parquet/Delta/Iceberg for the win).
You don’t need to implement all of this today. The point is: you’re not stuck. The notebook you wrote for Minikube is the same notebook you’ll run next quarter on EKS.
Field notes: little problems you’ll actually hit
- “Session stuck starting.” Usually resource pressure. Either give Minikube a bit more (
--memory 14336) or lower Spark requests/limits for the demo. ImagePullBackOff. Your node can’t reach the registry, or you needimagePullSecrets. Easy fix, don’t overthink it.- Slow reads on big datasets. You’re paying the tiny-file tax or skipping predicate pushdown. Compact to Parquet/Delta and filter early.
The good news: Ilum’s logs and metrics make these less mysterious. You’ll still debug—but with tools, not folklore.
Do you actually need Kubernetes for data science?
Strictly speaking? No. Plenty of useful analysis runs on a single machine. But as soon as your team grows or your data size stops being cute, Kubernetes buys you standardized environments, sane isolation, and predictable scaling. The more people share the same platform, the more those properties matter.
And the nice part is: with Ilum , moving to Spark on K8s doesn’t require tearing up your notebooks or learning the entire Kubernetes dictionary on day one. You point Jupyter/Zeppelin at a Livy-compatible endpoint and keep going.
Where to go next
- Keep this demo, but try a real dataset: NYC Taxi, clickstream, retail baskets, anything columnar and not tiny.
- Adicionar Spark event logging to object storage so the Servidor de Histórico can tell you what actually happened.
- If you’re on a cloud provider, deploy the same chart to GKE/EKS/AKS, add ingress + TLS, and connect SSO.
If you want a deeper dive, auth, storage classes, GPU pools for deep learning, or an example migration from YARN to Kubernetes, say the word and I’ll spin up a follow-up with concrete manifests.
Copy-paste corner
# Start local Kubernetes
minikube start --cpus 4 --memory 12288 --addons metrics-server
# Install Ilum with Jupyter, Zeppelin, and Livy proxy
helm repo add ilum https://charts.ilum.cloud
helm repo update
helm install ilum ilum/ilum \
--set ilum-zeppelin.enabled=true \
--set ilum-jupyter.enabled=true \
--set ilum-livy-proxy.enabled=true
# Open Jupyter and get the token
kubectl port-forward svc/ilum-jupyter 8888:8888
kubectl logs -l app.kubernetes.io/name=ilum-jupyter
# Open Zeppelin
kubectl port-forward svc/ilum-zeppelin 8080:8080
#Jupyter cell to test:
%load_ext sparkmagic.magics
%manage_spark # choose the predefined Ilum endpoint, then create session
%%spark
spark.range(0, 100000).selectExpr("count(*) as n").show()
A gentle nudge to try Ilum
Ilum is free, cloud-native, and built to make Spark no Kubernetes practical for actual teams—not just demo videos. You get the Livy-compatible endpoint, interactive sessionse logs/metrics all in one place, so your notebooks feel like notebooks again.